
Photo by Ivan Aleksic on Unsplash
Hello, developers! If you have worked on building deep neural networks, you might know that building neural nets can involve performing a lot of experimentation. In this article, I will share some tips and guidelines that I feel are pretty useful and can use to build better deep learning models, making it a lot more efficient for you to stumble upon a good network.
Also, you may need to choose which of these tips might be helpful in your scenario; everything mentioned in this article could straight up improve your models' performance.
A High-Level Approach for Hyperparameter Tuning
One of the painful things about training deep neural networks is the many hyperparameters you have to deal with constantly. These could be your learning rate α, the discounting factor ρ, and epsilon ε if you are using the RMSprop optimizer (Hinton et al.) or the exponential decay rates β�� and β�� if you are using the Adam optimizer (Kingma et al.). You also need to choose the number of layers in the network or the number of hidden units for the layers; you might be using learning rate schedulers and want to configure that and a lot more! We need ways to organize our hyperparameter tuning process better.
A common algorithm I usually tend to use to organize my hyperparameter search process is the random search. Though there exist improvements to this algorithm, I typically end up using random search. Let's say, for this example, you want to tune two hyperparameters, and you suspect that the optimal values for both would be somewhere between one and five. The idea here is to instead of picking 25 values to try out [like (1, 1) (1, 2), etc.] systematically, it would be more effective to select 25 points at random.
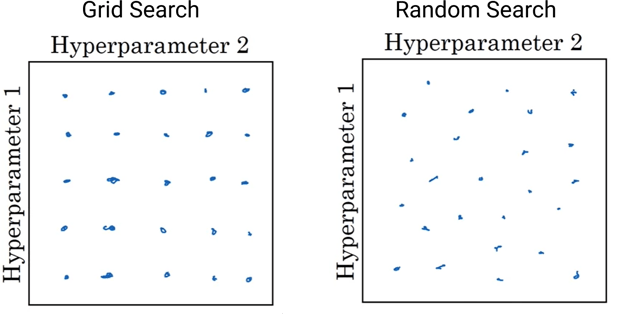
Based on Lecture Notes of Andrew Ng
Here is a simple example with TensorFlow where I try to use random search on the Fashion-MNIST dataset for the learning rate and the number of units:
Radom Search in TensorFlow.
I would not be talking about the intuition behind doing so in this article. However, you could read about it in this article I wrote some time back.
Use Mixed Precision Training for Large Networks
Growing the size of the neural network usually results in improved accuracy. As model sizes grow, the memory and compute requirements for training these models also increase. While using mixed-precision training, according to Paulius Micikevicius and colleagues, the idea is to train deep neural networks using half-precision floating-point numbers to train large neural faster with no or negligible decrease in the performance of the networks. However, I would like to point out that this technique should be used only for large models with more than 100 million parameters.
While mixed-precision would run on most hardware, it will only speed up models on recent NVIDIA GPUs, for example, Tesla V100 and Tesla T4 and Cloud TPUs. To give you an idea of the performance gains with using mixed precision when I trained a ResNet model on my Google Cloud Platform Notebook instance (consisting of a Tesla V100) I saw almost 3 times in the training time and almost 1.5 times on a Cloud TPU instance with near to no difference inaccuracies. To further increase your training throughput, you could also consider using a larger batch size (since we are using float16 tensors, you should not run out of memory).
It is also rather easy to implement mixed precision with TensorFlow, the code to measure the above speed-ups was taken from this example. If you are looking for more inspiration to use mixed-precision training, here is an image demonstrating speedup for multiple models by Google Cloud on a TPU:
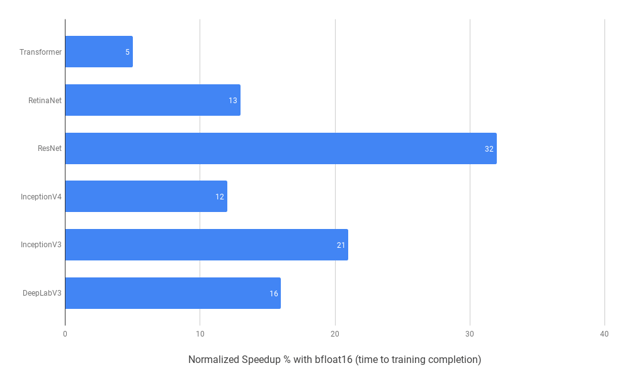
Speedups on a Cloud TPU
Use Grad Check for Backpropagation
In multiple scenarios, I have had to custom implement a neural network, and usually implementing the backpropagation is the aspect prone to mistakes and is also difficult to debug. It could also occur that with an incorrect backpropagation, your model learns something that might look reasonable, thus making it even more difficult to debug. So, how cool would it be if we could implement something that could allow us to debug our neural nets easily?
I often consider using gradient checks when implementing backpropagation to help me debug it. The idea here is to approximate the gradients using a numerical approach. If it is close to the calculated gradients by the backpropagation algorithm, then you could be more confident that the backpropagation was implemented correctly.
As of now, you could consider using this expression in standard terms to get a vector, which we will call dθ[approx]
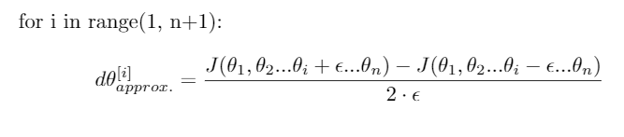
Calculate approx gradients
In case you are looking for the intuition behind this, you could find more about it in this article by me. So, now we have two vectors dθ[approx] and dθ (calculated by backprop). And these should be almost equal to each other. You could simply compute the Euclidean distance between these two vectors and use this reference table to help you debug your nets:

Reference Table
Cache Datasets
Caching datasets is a simple idea but one I have not seen much to be used. The idea here is to go over the dataset in its entirety and cache the dataset either in a file or in memory (if it is a small dataset). This should save you from performing some expensive CPU operations like file opening and data reading from being executed during every single epoch. Well, this also means that your first epoch would comparatively take more time since you would ideally be performing all operations like opening files and reading data in the first epoch, and then you would cache them. The subsequent epochs should be a lot faster since you would be using the cached data in the subsequent epochs.
This particularly seems like a very simple to implement the idea, indeed! Here is an example with TensorFlow showing how one can very easily cache datasets and also shows the speedup with implementing this idea:

Example of Caching Datasets and the Speedup with It
Common Approaches to Tackle Overfitting
If you have worked on building neural networks, it is arguable overfitting or underfitting might be one of the most common problems you face. This section talks about some common approaches that I usually use when tackling these problems. You probably know this, but high bias will cause us to miss a relation between features and labels (underfitting), and high variance would cause capturing the noise and overfitting to the training data.
I believe the most promising way to solve overfitting is to get more data, though you could also augment data. A benefit of deep neural networks is that their performance improves as they are fed more and more data. A benefit of very deep neural networks is that their performance continues to improve as they are fed larger and larger datasets. However, in a lot of situations, it might be too expensive to get more data (or simply infeasible to do), so let's talk about a couple of methods you could use to tackle overfitting.
Ideally, this is possible to do in two manners: either changing the architecture of the network or by applying some modifications to the network's weights. A simple manner to change the architecture such that it doesn't overfit would be to use random search to stumble upon a good architecture or try pruning nodes from your model. We already talked about random search, but in case you want to see an example of pruning, you could take a look at the TensorFlow Model Optimization Pruning Guide.
Some common regularization methods I tend to try out are:
-
Dropout: Randomly remove x% of input.
-
L2 Regularization: Force weights to be small reducing the possibility of overfitting.
-
Early Stopping: Stop the model training when performance on the validation set starts to degrade.
Thank You
Thank you for sticking together with me till the end. I hope you will benefit from this article and incorporate these in your own experiments. I am excited to see if it helps in improving the performance of your neural nets, too. If you have any feedback or suggestions for me, please feel free to send them over! @rishit_dagli