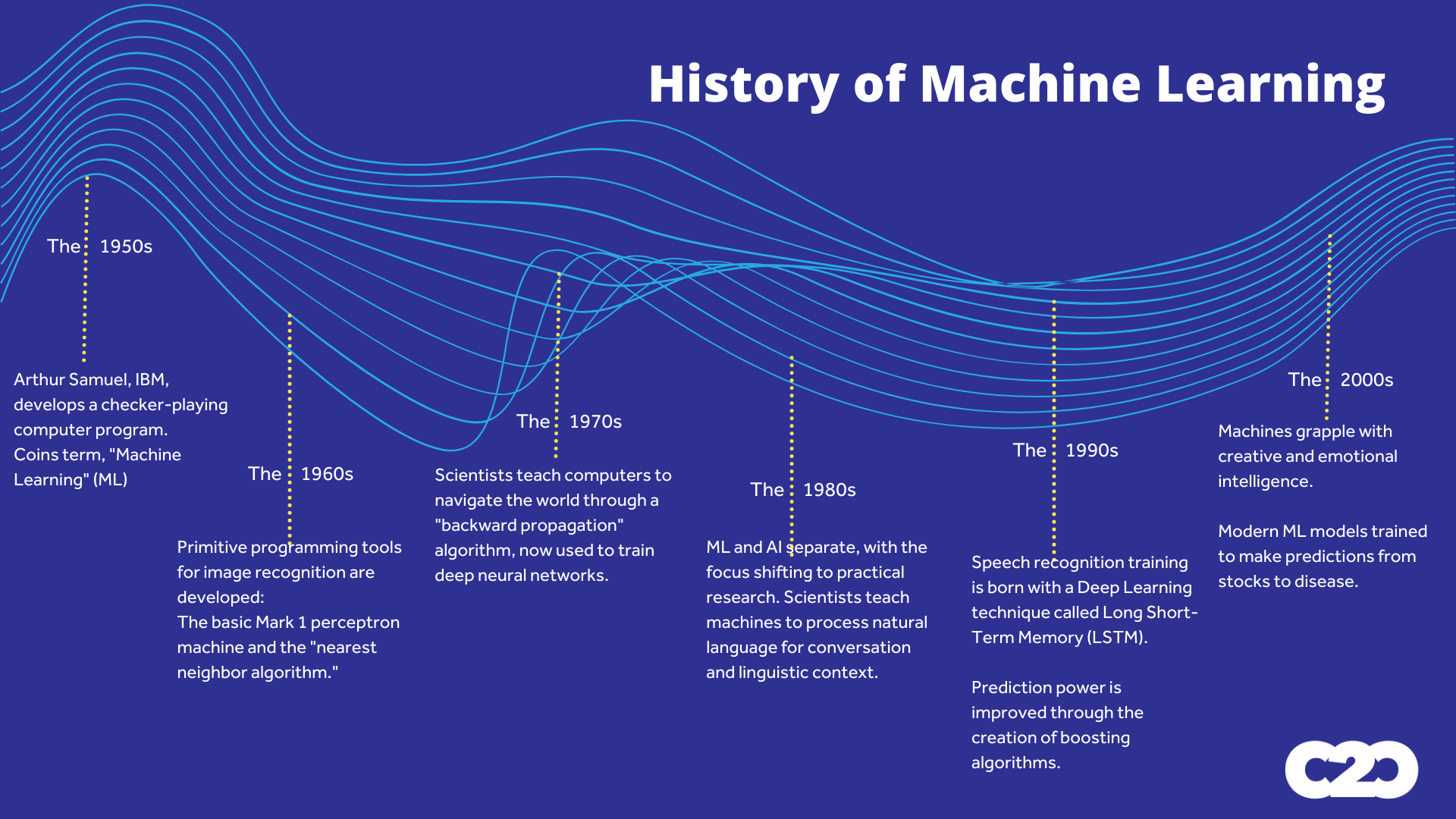
How do you teach a machine to think like humans? That question is the central challenge of ML.
Humans reason in causal, probabilistic, and intuitive ways, but machines function primarily in the binary. To make the machine think like humans, data scientists analyze abstract human mental models and convert them into binary digits or computer language.
The benefits of such training or having machines at all is to crunch vast amounts of data in a short amount of time. Machines can tackle descriptive, predictive, or prescriptive problems, and depending on the machine’s application, scientists develop the correct algorithm and design a training process for their project. They train the machine and repeatedly test it until it achieves perfect results.
As a topic that generates a lot of discussion and interest from the C2C community, particularly when they’re getting started with bringing AI or ML into their stacks, we set out to create this cheat sheet to make it easier.
ML Learning Models
Scientists teach machines to analyze, predict, and advise on possible outcomes using these common learning styles:
- Supervised Learning: Practitioners train the machine on labeled inputs paired with labeled outputs, teaching it to make associations.
- Example: A shape with three sides is marked “triangle.” Supervised learning is the more common model used for situations that involve classification, regression modeling, and forecasting.
- Unsupervised Learning: The algorithm sifts through the given unlabelled data, identifying patterns, such as how many sides a shape has. The model’s decision-making improves with data iteration. Unsupervised learning is ideal for tasks like clustering and anomaly detection.
- Semi-Supervised Learning: Scientists feed labeled and unlabeled data to the model, and the combination helps the algorithm identify successive unlabeled data.
- Reinforcement Learning: Negative reinforcers and positive reinforcers program the machine and interact with its environment. Reinforcement learning is often used in robotics.
- Transfer Learning: Scientists apply training from one model to another with a related but different issue.
The most Common ML Algorithms
- Artificial Neural Networks (Reinforcement Learning): Artificial Neural Networks (ANNs) model how our brains analyze and process information, using the same simulation of neurons, synapses, nodes, and neural firing. Most ANNs are used for pattern matching and “learning rules,” where the network learns from previous examples.
- Deep Learning Algorithms (Reinforcement Learning): Deep Learning (DL) methods, the modernized version of ANNs, build more extensive and more complex neural networks than ANNs. Many of the DL methods use large datasets of labeled analog data, e.g., image, text, audio, and video.
- Decision Tree Algorithms (Supervised Learning): Decision trees are tree-like structures with “branches” that show all possible outputs and leaf nodes corresponding to class labels and attributes and used for classification and regression, and, being fast and accurate, are a standard ML tool.
- Regression Algorithms (Supervised Learning): Regression models show the positive or negative correlations between two or more variables and help classify and predict.
- Bayesian Networks (Supervised Learning): The relatively simple Bayes Theorem, used to determine the probability, is often used for problems such as classification and regression.
- Clustering Algorithms (Unsupervised Learning): Clustering algorithms identify patterns and cluster data into sets of specific groups.
- Instance-Based Algorithms (Supervised Learning): Instance-based learning (also called memory-based learning or lazy-learning) is where the model compares new problem instances with data added previously.
- Association Rule Learning Algorithms (Reinforcement Learning/Supervised Learning): Association rule learning uses rules for discovering connections between variables in large groups of data and is used for forecasting, prediction, and analysis.
Building an ML Workflow
To train a computer model, ML practitioners execute the following process:
- Gathering Data: The quality and quantity of the model’s data determine the accuracy of its results. This data is called the “training set.”
- Data Preparation: Data scientists load the data, split it into training or evaluating, and perform tasks like pattern recognition, anomaly detection, or error correction to adjust and manipulate the data.
- Choosing a Model: Each model has its function. Some models suit text-based data, while others work best for image data, numerical data, or sequence-based data, like text or music.
- Training: Scientists use the data to create ML algorithms to teach the model to describe, predict, or prescribe. They train and retrain the model for desired results. Each iteration is called a “step.”
- Evaluation: Scientists test their model against the original dataset to see how their model performs in the real world.
- Parameter Tuning: Scientists fine-tune their parameters (also called “hyperparameters”) to see whether they can improve the model in any way, for example, in its accuracy or learning rate.
- Prediction: Scientists use their finished model to analyze situations, predict the future, or advise on possible outcomes.
Limitations of ML
- Algorithmic Bias: Computer models are not objective thinkers since they’re programmed by subjective humans, leading to bias in criminal justice, health care, and hiring.
- Reasoning Constraints: Certain human cognitive processes are beyond the machine’s capacity. These include imagination, the ability to ask questions, and to contextualize.
- Time Constraints in Learning: Since ML models need huge and reiterated datasets for accurate predictions, it is almost impossible to get immediate, accurate predictions.
ML Applications
ML is used across industries in countless ways, including:
- Health Care: ML detects diseases in their early stages with high-degree accuracy, helping us prevent and cure disease.
- Finance: ML helps the finance industry streamline and optimize decisions from underwriting to quantitative trading and financial risk management.
- Object Detection: ML helps us recognize, locate, and detect multiple objects in real time. Critical areas include video surveillance, crowd counting, and self-driving cars.
- Risk Detection and Predictive Analysis: These include spam filtering, best-to-date insider threat detection, optical character recognition (OCR), and search engines.
- Marketing and Advertising: ML transforms advertising from ad creation and audience targeting to ad buying by, for example, targeting consumers with ads based on their browser performance.
What's Next?
Predictions include the following:
- Future of Healthcare: Identifying ML can be used to detect early-stage diseases with far greater accuracy, possibly even before we become ill.
- Manufacturing Robots: There will be a perfect collaboration between humans and robots, with robots performing more flawlessly than now.
- Future of Finance: You will be able to do your taxes without lifting a pen. Fraud detection and trading will be more accessible, financial planning more advanced.
- Natural Language Processing (NLP): Today’s conversational AI is limited to specific tasks. Future virtual assistants will be able to solve more complex and context-based queries.
- Immortality: We may be able to digitally copy the brain’s structure and download our minds into a computer, living after we die through a computer simulation.
Extra Credit
- Journal of Machine Learning Research
- IEEE Transactions on Pattern Analysis and Machine Intelligence
- Information Fusion
- Nature Machine Intelligence
- Neural Computation
Let's Connect!
There is so much more to discuss, so connect with us and share your Google Cloud story. You might get featured in the next installment! Get in touch with Content Manager Sabina Bhasin at sabina.bhasin@c2cgobal.com if you’re interested.
Rather chat with your peers? Join our C2C Connect chat rooms!