Prefetch
At the Google Cloud Born-Digital Summit 2021 (08:50) Diana Nanova from Google Cloud was asking: "how do you actually scale?". At that time history as well as the setup was briefly explained. Additionally, the k8s hpa topic was touched and also described that just cpu based hpa scaling is used at the moment. As CPU is just a general indicator of load - it is quite a rough estimation about scaling should be done or not. Especially if cpu load is low but number of incoming requests is high and if there are 500 different components running with different internal behaviors - this kind of scaling is suboptimal. So it was explained there are smarter ways to do it with custom metrics to use for example rpm/rps (incoming requests per minute/second) or queue size of tasks to be done. One important answer given in the summit video regarding scaling: "Why just spawning 1, 2, 4, 10 replicas - why not spawning 10.000 as many messages you have in the queue? If autoscaling on node level works - this is also an option". Here it is - a small usecase in a defined environment showing the advantage of massive scaling based on a message queue:

Precondition
Something you should know in advance of reading this article - as it will not be explained:
-
container-orchestration system kubernetes
-
containers, workloads, pods, deployments and resource definitions of it
-
concept of hpa scaling in kubernetes
-
concept of stateless workloads
-
concept of "unit of work"
-
concept difference between message queue, pubsub, consumer-grouping
-
concepts of messaging systems like activeMQ, hornetQ, artemis, kafka, Google GCP Pubsub
-
what are slow (lagging) consumers
-
helm and how it works
-
monitoring with prometheus grafana stack
-
java, spring -
Goal
So whats the ultimate goal of this experiment?
Showcase the container+node scaling (up and down) of consumers/processors by number of elements in a queue. As business case example the processing (analyzing and extracting) of pdf documents is used.
-
Primary target is to technically showcase this is possible.
-
Secondary target is to have an optimized monetary outcome here by having low or no costs in 'idle' mode and real processing costs if elements get processed.
-
Tertiary target optimize current slow consumer processing to address current issues:
-
rebalancing of consumer groups takes too much time on scaling
-
processing across partitions (if one consumer is idle)
-
parallel processing is limited to the number of partitions
-
-
Tertiary target is to have (as we run a multitenant environment) a better fair tenant processing:
-
current strategy: first come - first serve
-
single events might block processing of following events
-
processing time of batches seems not linear (hard to ETA)
-
Current state
So where do we come from and how does it look at the moment?
At the moment the full environment is based on k8s - so all the workload is containerized and deployed to this orchestration framework. However scaling was always difficult as the hardware environment was not supporting it at all (baremetal k8s cluster - and ordering of machines just took days or even a week to complete) or caused unexpected or unpredictable system behavior (on other cloud provider). This dramatically changed since we are running our clusters on Google GCP. All the clusters where migrated to GKE and since then everything works as expected.
The business case of the pdf document processing is a core feature of marketlogic. It is of interest to extract all useful information out of binary documents. This can be text, structue of the document, entity detection, images and so on. All of these processing parts have something in common: they are not done in some milliseconds but take some more time (up to minutes). All kinds of exceptions can occur - corrupted or malformed input, super slow processing, super large embedded elements, thousands of pages.
This directly leads to an explanation of the tertiary targets - in the current solution there are two more suboptimal topics. One is slow and lagging single consumers and other one is unbalanced consumer groups. The following picture is visualizing the situation. Each color is a consumer and shows the % distribution across the consumers. Especially at the end of the graph you can see what only a few consumers are left with tasks to do. However, other idle consumers cannot help with remaining tasks and sit idle. Additionally, we let the consumers sit idle on the hardware even if there is no processing to be done - so there is currently no scaling at all - just idling.
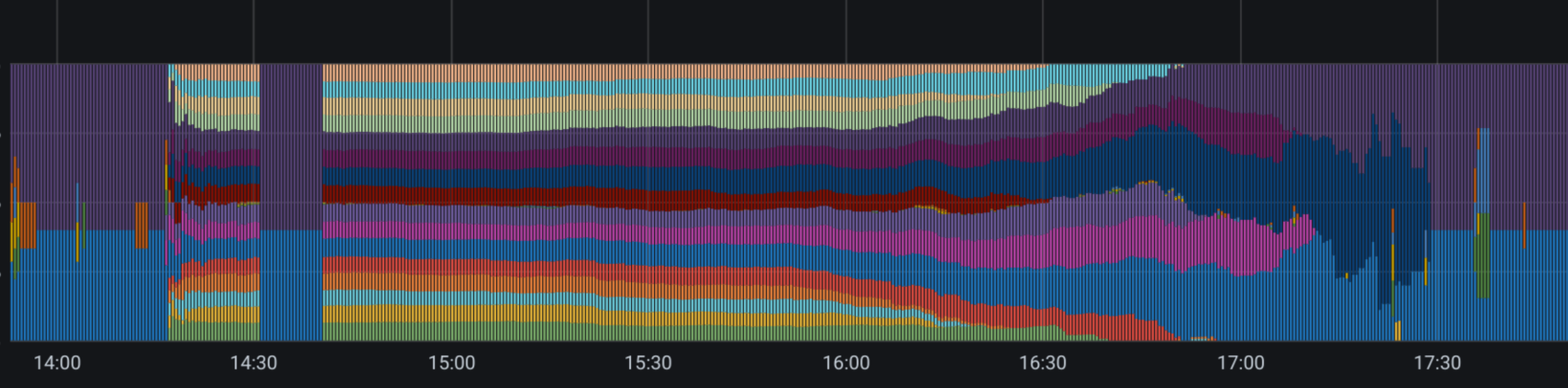
One point to always keep in mind is fair tenant processing. Let's take a look on the following fact: in multi tenant environments customers share resources. If the message consumption strategy is 'first come - first serve' it implies - if a tenant/customer is generating a lot of load and events - others will have to wait (they are blocked) for their events to be processed till the first (big) one is finished. On the opposite side - if you don't keep the 'first come - first serve strategy' - that would imply your events need get out of order. The environment/ system needs then to be aware of potential racing conditions.
Target Setup
The target setup is a balance of the current existing environment and some fancy new stuff - to also showcase the bridging capabilities between the as it is state and what it could be.
-
kubernetes 1.18+ on gcp gke as container runtime environment
-
kubernetes 1.18+ on gcp gke autopilot in bonus section as container runtime environment
-
gcp gke autosizing nodepool 0-20 nodes (gke cluster-autoscaler)
-
gcp pubsub as messaging system
-
gcp bucket as storage, user interface and event generator (see next line)
-
gcp bucket pubsub notifications add gcp bucket events to a topic
-
keda.sh as kubernetes custom hpa scaler for gcp pubsub
-
quarkus as application stack for apache camel
-
Apache Camel as EIP gluing for gcp pubsub and gcp bucket
-
Eclipse microprofile for app insight metrics
-
Prometheus as metric scraping (k8s default) for Eclipse microprofile
-
Grafana as visualisation tool for Prometheus
So main idea for the showcase is to have a hardware autoscaling k8s cluster, gcp bucket as event generator and gcp pubsub as message queue. pubsub has two advantages here - its ack per single message and it has no message ordering per default. keda.sh k8s custom hpa scaler is the gluing between the message queue system (there are several supported - in this case we take the pubsub gluing) and the k8s hpa. As business application a quarkus app is used (could be also a java spring one - just to be fancy here). Finally to glue the event consumption apache camel is used. To be able to get some insights and visualizations quarkus, camel (but also spring) can be extended by adding microprofile to expose metrics. Scraping and visualization is then done as usual in k8s via prometheus and grafana.
To generate a lot of events (to then have a reason to massive scale) out of a single user interaction following scenario is used. Out of one manually uploaded pdf document one gcp bucket storage event is generated and pushed to a given topic. This single event will be consumed by a subscriber which will generate other files (pagemarker) per page of the document (that then generate other events by storage layer again). This will multiply the number of events already by 100 (if the document has 100 pages). Each of the events will represent a single page of the pdf document then and will generate another event per feature to be applied on the pdf page. This can be text extraction, image rendering of the page, vectorization for further AI/ML processing and structure detection. So as these are 4 features - out of the 100 events (for 100 pages) - 400 events will be generated in the end. You can imagine this snowballing could continue if additional features like language detection, translations to different languages and ocr would be applied.
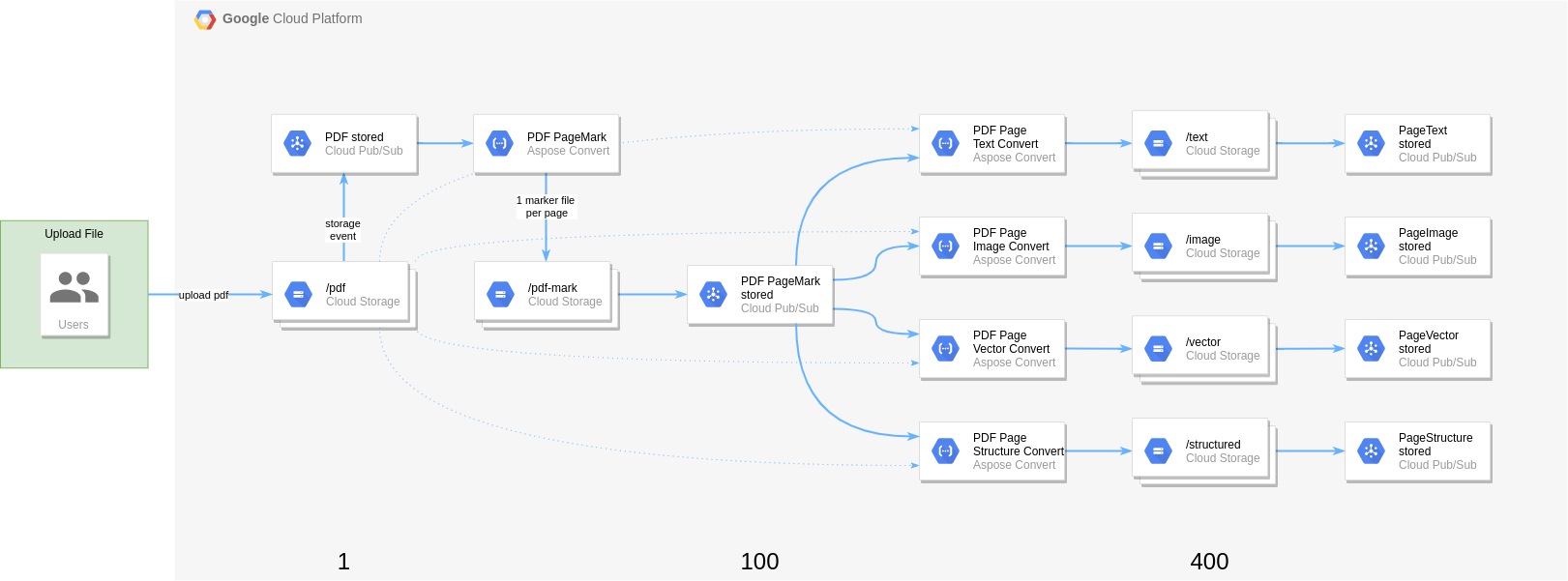
How does this look like from the internals - per change (create, update, delete) on GCP Storage Bucket events are triggered that can be forwarded to a topic of your choice:
gsutil notification create -t TOPIC_NAME -f json gs://BUCKET_NAME
As GCP PubSub is supporting creating subscriptions (where consumers listen to) with filters - lets register to a file create event n the /pdf subfolder of the bucket:
gcloud beta pubsub subscriptions create rennicke-test-pdf-pagemark \
--topic=rennicke-test \
--expiration-period=never \
--ack-deadline=300 \
--min-retry-delay=60 \
--max-retry-delay=600 \
--message-retention-duration=1d \
--message-filter='attributes.eventType="OBJECT_FINALIZE" AND hasPrefix(attributes.objectId, "pdf/")' \
--project $(GCLOUD_PROJECTID)
Afterwards "file created" events (OBJECT_FINALIZE) will become avail on the subscription and can be consumed by the subscribers. This is how an event looks like (headers and body) in the camel EIP gluing.
{objectGeneration=xyz, eventType=OBJECT_FINALIZE, eventTime=2021-05-01T15:42:41.028609Z, bucketId=rennicke-test, objectId=pdf/vehicle.pdf, payloadFormat=JSON_API_V1, notificationConfig=projects/_/buckets/rennicke-test/notificationConfigs/2}
{
"kind": "storage#object",
"id": "rennicke-test/pdf/vehicle.pdf/zyz",
"selfLink": "https://www.googleapis.com/storage/v1/b/xyz",
"name": "pdf/vehicle.pdf",
"bucket": "rennicke-test",
"generation": "xyz",
"metageneration": "1",
"contentType": "application/pdf",
"timeCreated": "2021-05-03T15:41:46.524Z",
"updated": "2021-05-03T15:41:46.524Z",
"storageClass": "STANDARD",
"timeStorageClassUpdated": "2021-05-03T15:41:46.524Z",
"size": "xyz",
"md5Hash": "xyz==",
"mediaLink": "https://www.googleapis.com/download/storage/v1/b/xyz/",
"crc32c": "xyz==",
"etag": "xyz="
}
GCP PubSub messages dont have an order per default so means if a mass upload of files or any events happening message consumption will be random on the remaining no acked messages. For this showcase this already fits then the fair tenant processing requirement target given. Additionally, as soon as a processig step is done - a new file is generated in another folder. If that folder then has ne or more subscriptions with same filter - you can imagine this will start to scale as described in the overview picture.
Most important step to make this experiment running is the use of the custom hpa scaler from keda.sh. This supports several different messaging systems to have the hpa workig depending on queue size. Keda can be installed via a helm install and provides a crd to define the scaling behavior. hint: using own hpa.yaml and this crd at the same time is clashing. Installation scripts can be found here. To have the glueueing to keda gcp pubsub a custom resource needs to be deployed that looks like this:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
labels:
app.kubernetes.io/instance: google-document-convert
app.kubernetes.io/name: google-document-convert
name: google-document-convert
spec:
scaleTargetRef:
name: google-document-convert
pollingInterval: 5 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds - only applies if minReplicaCount=0 and scale from 1 to 0
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
triggers:
- type: gcp-pubsub
authenticationRef:
name: google-document-convert
metadata:
subscriptionSize: "2"
subscriptionName: "rennicke-test-pdf-pagemark" # Required
So this will will watch the subscription "rennicke-test-pdf-pagemark" on gcp-pubsub and start scaling if there are more than 2 messages in per avail pod in average. It will even scale down to 0 if there are no events in the queue.
Last but not least the most important part for the money saving is this feature: GCP GKE cluster-autoscaler. So inside the gke cluster a nodepool needs to be present with autoscaling feature on and minimum number of nodes set to 0 - maximum can be any number that fits.
Some words about the visibility and metrics as people tend to dont care or dont need or dont want. Its always important to have insights of your current running process. Especially in distributed systems this becomes a critical part. For java and spring you have libraries like microprofile or micrometer to (more or less) flawlessly give metric exposing via some management endpoint (like spring actuator). The only thing required then to bring it togeather with k8s metrics to have it exposed in prometheus format and have a service monitor deployed. For apache camel micrometer statistics will already expose metrics about EIP routes executed, timings and jvm metrics - so adding a single dependency to the project - it gives already a lot of information.
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
annotations:
labels:
app.kubernetes.io/instance: google-document-convert
app.kubernetes.io/name: google-document-convert
prometheus: kube-prometheus
name: google-document-convert
spec:
endpoints:
- interval: 30s
path: /q/metrics
port: business
selector:
matchLabels:
app.kubernetes.io/instance: google-document-convert
app.kubernetes.io/name: google-document-convert
Lets run!
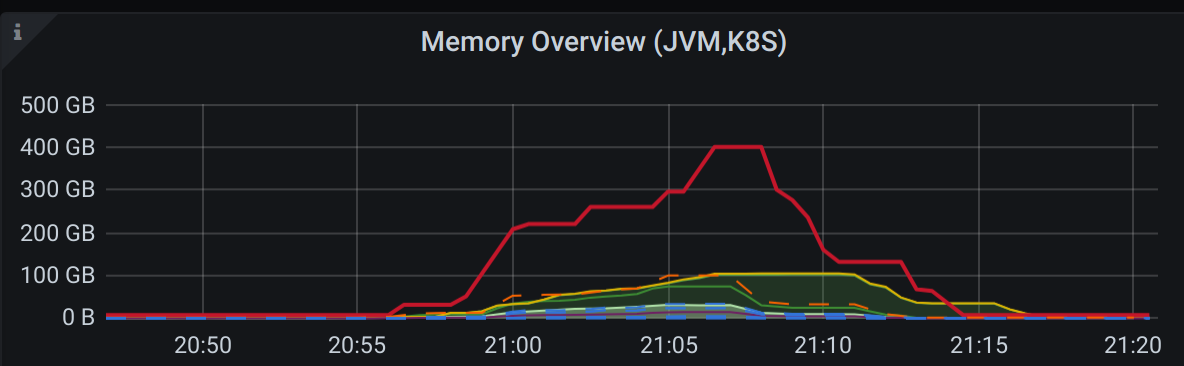
Ok, so you might have wondering why i gave such a large stack to showcase something simple right? Well i wanted to facilitate some of the internal metrics and bring it all together in a single grafana dashboard chart. So here you can see requested container memory (red line), container used memory, jvm metrics and so on. But however details dont matter :) - its just about the graph goes up to a certain maximum and then goes down afterwards to some idle number or even 0. To trigger all the scaling all i did was to upload lots of pdf files to /pdf folder of the gcp bucket.
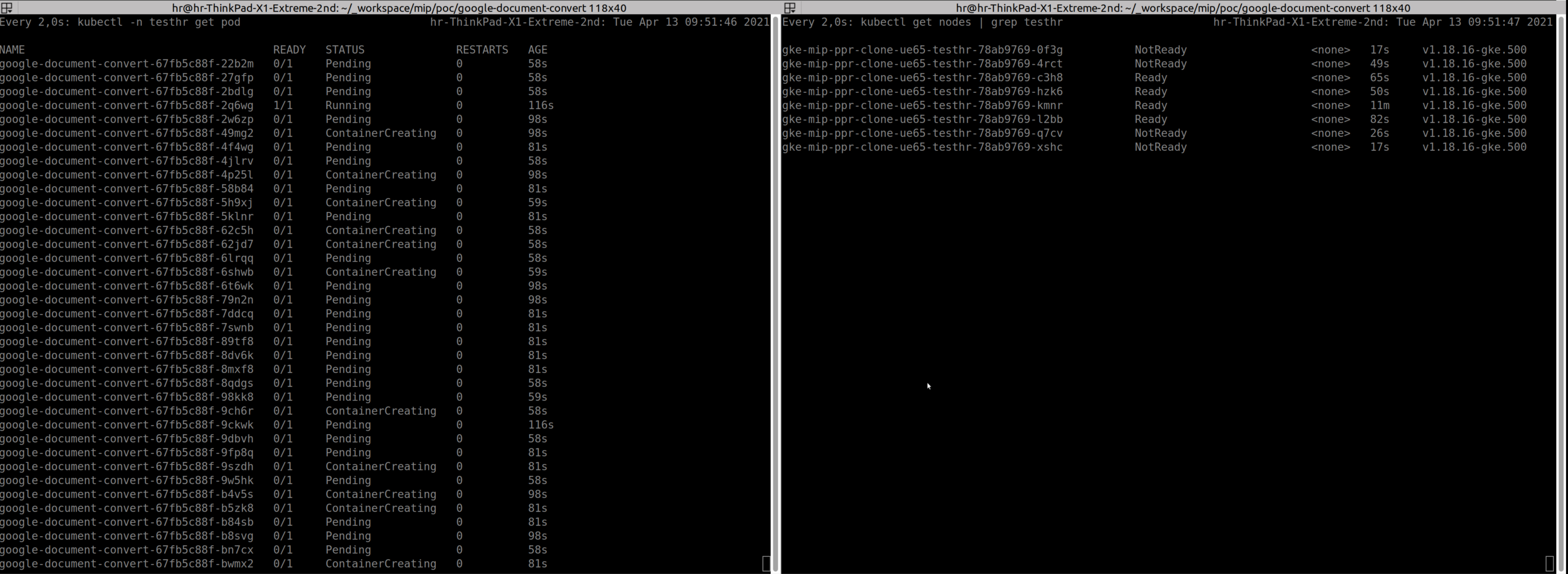
While this graph is already fancy - seeing the scaling on pod level and even better on hardware level is more impressive. So in the following picture you see on the left side lots of pending pods - as they are waiting for the nodes (on the right side) to be created. As this is just taking some seconds the scaleup is delayed - but still in a useful time manner present. So in my usecase about 100 pods get spawned within about 5-10 minutes without any tweaking of the default GKE settings and with number of active pods and active nodes == 0 at the beginning. After the full scale level is reached ad number of events in queue gets empty scaledown of pods and later on also nodes get trigged. This is exactly the point where the monetary win kicks in - you dont need to have hardware sitting around idle but can just wait for the queue to spawn pods and at this stage hardware autmatically on demand.
Conclusion
So its fancy, its cool, its impressive to see and easy to install. Its exactly whats fitting the given requirements from the moneytarization target. There is just one drawback i can see for now - the ramp up time of 3-5 minutes might not work if it should be used for synchronous UI interactions. For async, job or queue based stuff this seems very usable to me.
Bonus Section
Every works everything is cool. Lets make it a bit more fancy. latly Google cloud released the GCP GKE Autopilot feature which offered a fully managed K8s environment where billing goes on pod level - so pay what you use. So if you dont use any automation you can create a new autopilot gke cluster with just 3 clicks in the google cloud console.
For the bonus section i did not do any fancy automation - as it is just 3 clicks ahead in the google cloud console ui:
-
go to project of your choice and go to GKE section
-
click create autopilot gke cluster
-
enter name and region
-
ignore private mode for now (dont do that in production)
-
click create
-
click connect via cloud console and you have kubectl access to the autopilot generated clust
her@cloudshell:~/$ gcloud container clusters get-credentials autopilot-testhr --region europe-westX --project XYZ
her@cloudshell:~/ (xyz)$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gk3-autopilot-testhr-default-pool-0bc316b4-zwqn Ready <none> 28m v1.18.16-gke.2100
gk3-autopilot-testhr-default-pool-ba54c56c-b7r7 Ready <none> 28m v1.18.16-gke.2100
Next step is to install keda as minimal running setup (and ignore gafana and prometheus metric exposing for now). Installing the defaults are failing as nodeselectors are not supported in that way and additionally one rolebinding is namespaced to kube-system.
her@cloudshell:~/ (xyz)$ curl -L https://github.com/kedacore/keda/releases/download/v2.2.0/keda-2.2.0.yaml > keda-2.2.0.yaml
- deployments cant be applied - so need to be removed beforehand:
nodeSelector:
beta.kubernetes.io/os: linux
- kind: RoleBinding name: keda-auth-reader should be keda? (namespace: kube-system)
her@cloudshell:~/ (xyz)$ kubectl apply -f keda-2.2.0.yaml
namespace/keda created
customresourcedefinition.apiextensions.k8s.io/clustertriggerauthentications.keda.sh created
customresourcedefinition.apiextensions.k8s.io/scaledjobs.keda.sh created
customresourcedefinition.apiextensions.k8s.io/scaledobjects.keda.sh created
customresourcedefinition.apiextensions.k8s.io/triggerauthentications.keda.sh created
serviceaccount/keda-operator created
clusterrole.rbac.authorization.k8s.io/keda-external-metrics-reader created
clusterrole.rbac.authorization.k8s.io/keda-operator created
clusterrolebinding.rbac.authorization.k8s.io/keda-hpa-controller-external-metrics created
clusterrolebinding.rbac.authorization.k8s.io/keda-operator created
clusterrolebinding.rbac.authorization.k8s.io/keda:system:auth-delegator created
service/keda-metrics-apiserver created
apiservice.apiregistration.k8s.io/v1beta1.external.metrics.k8s.io created
[...]
Then just deploy the app as on a normal K8s or GKE cluster. Afterwards check the keda scaledobject - as it will give you a hint if it is ready and active (should be true for the first one and false for the second).
her@cloudshell:~/deployment (xyz)$ kubectl -n testhr get pod
No resources found in testhr namespace.
her@cloudshell:~/deployment (xyz)$ kubectl -n testhr get scaledobject
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE AGE
google-document-convert apps/v1.Deployment google-document-convert 0 100 gcp-pubsub google-document-convert True False 76s
Then the same procedure as described above with mass uploading pdfs to the gcp storage bucket was done. The pods as well as the nodes started to autospawn.
her@cloudshell:~/deployment (xyz)$ kubectl -n testhr get pod | grep Running | wc -l
68
her@cloudshell:~/deployment (xyz)$ kubectl -n testhr get nodes | wc -l
74
Whats next?
-
run same example on GCP GKE Autopilot (to pay per usage)
-
run extended feature with GCP Document AI for document structure analysis
-
run extended feature with document automl entity extraction
-
run extended feature with google vision
-
extended deepdive into microprofile + dashboard deploy + prometheus + grafana